第一映像
zipkin是一个分布式跟踪系统。用于收集分布式系统中的日志数据。拥有数据的收集和查找功能,现在可以通过docker镜像和jar包的方式运行。
如果日志文件中有trace ID,则可以直接跳至该trace ID。否则,您可以基于下面这些属性进行查询,例如service, operation name, tags and duration。zipkin会帮你总结,在服务中花费的时间百分比等情况。
查询方式如下:
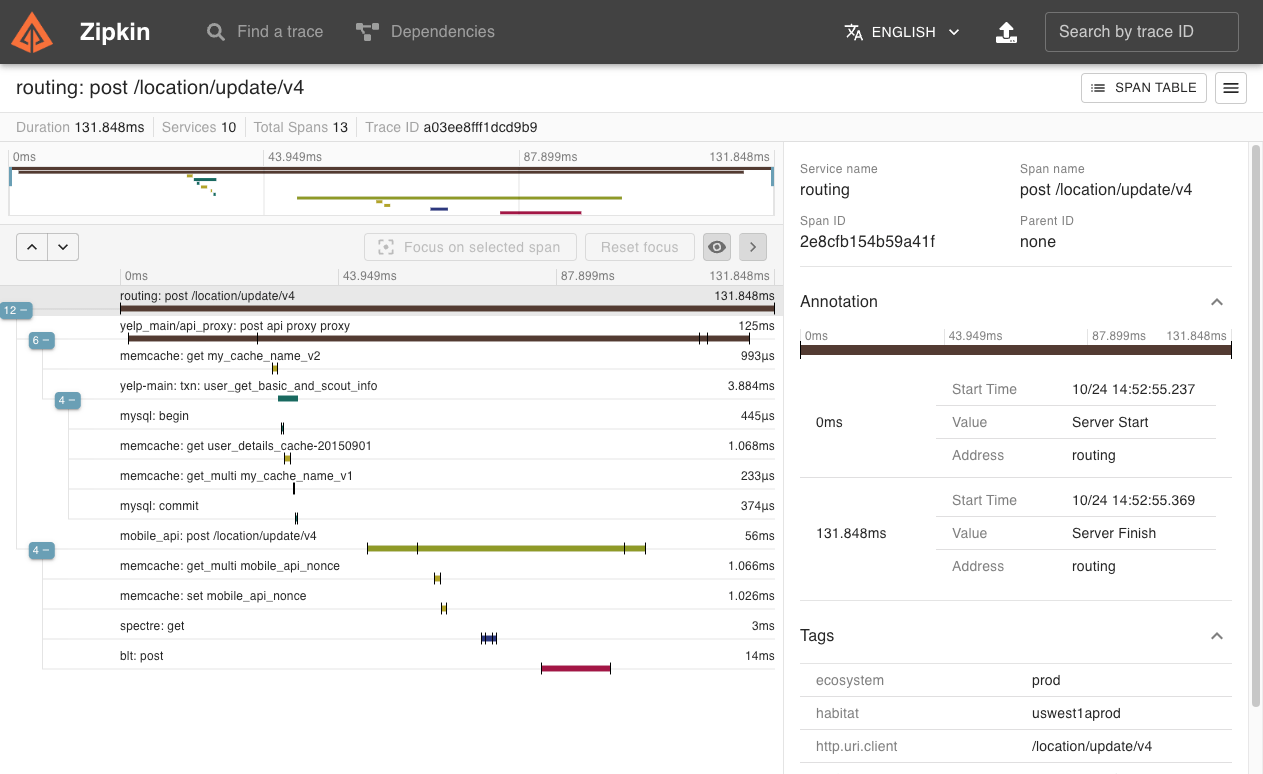
查询结果展示:
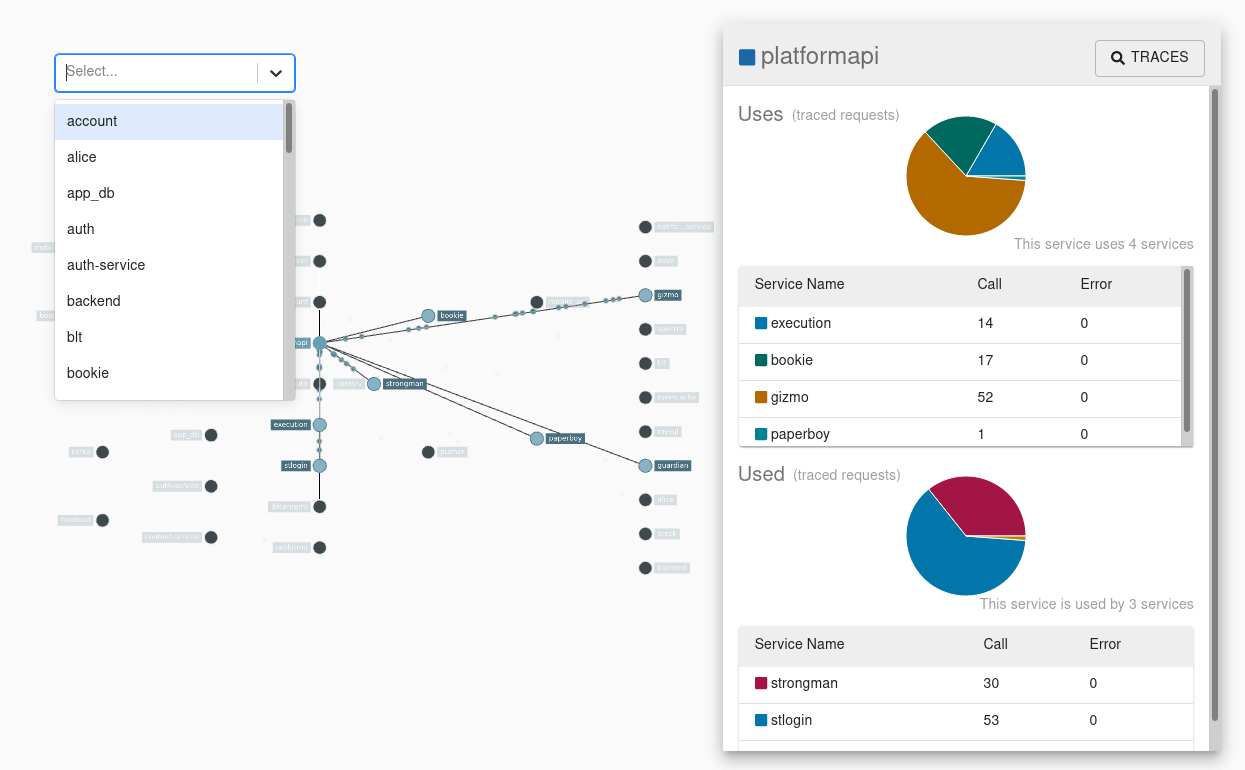
服务依赖展示:
数据流图
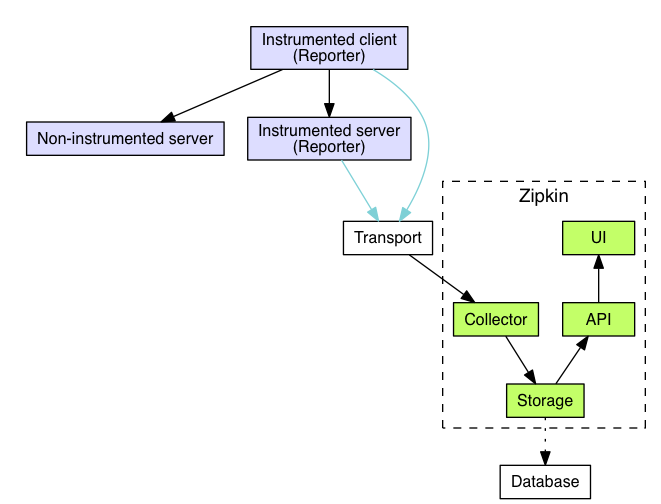
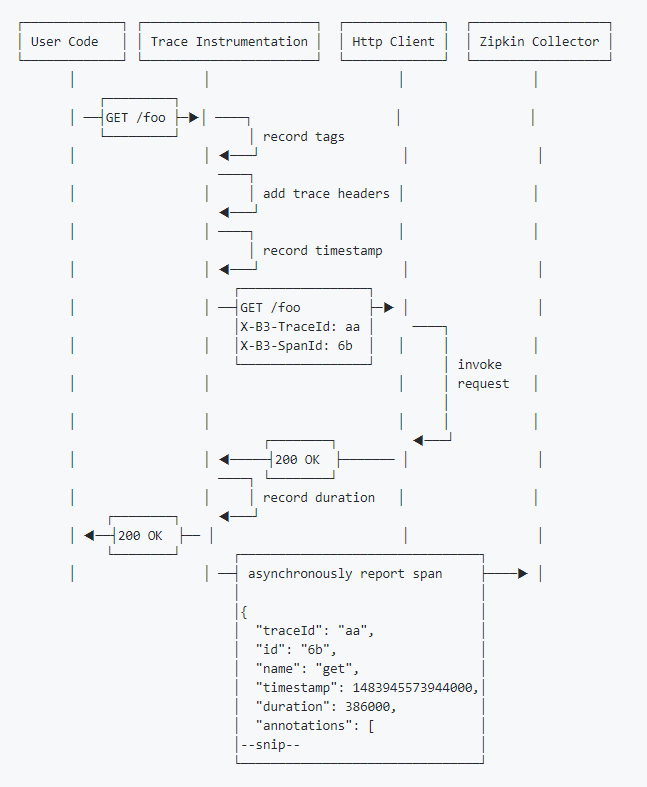
服务记录流程:
组件
Zipkin由4个组件组成:
- collector
- storage
- search
- web UI
Zipkin Collector
trace data 到达Zipkin收集器守护程序后,将对其进行验证,存储和索引以供Zipkin收集器进行查找。
Storage
zipkin最初构建存储使用的是Cassandra ,现在也原生支持ElasticSearch and MySQL,另外可能还有一些第三方的扩展存储。
Zipkin Query Service
数据存储和索引之后就需要抽取展示它,查询的守护进程提供了一个简单的json api 来查找和提取traces。 数据主要的消费者就是WEB UI。
Web UI
WEB UI提供了方法来展示traces ,可以通过服务、时间和注释等方式来展示。WEB UI没有内置的认证(登录)服务。
常见用法
trace相关的instrument对照列表见 tracers_instrumentation
常用spring cloud微服务应用可以引入相应的依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
指定相应的配置如下即可
spring:
zipkin:
base-url: http://zipkinservice #指定zipkin service url
sender:
type: web # 指定传输方式为 http 方式,另外支持rabbitmq 和 kafka